
 Cloud Visibility
Cloud Visibility
 Application Performance
Application Performance
 Network Performance Optimization
Network Performance Optimization
 Security
Security
 Industries
Industries
 Platform
Platform
 About Us
About Us
 Learn
Learn
 Blogs
Blogs
 Improved delivery, better visibility: How Accedian and VMware are working together to help CSPs navigate the 5G world
Improved delivery, better visibility: How Accedian and VMware are working together to help CSPs navigate the 5G world
 Adding a new dimension of visibility to the Cisco Full-Stack Observability portfolio with Accedian Skylight
Adding a new dimension of visibility to the Cisco Full-Stack Observability portfolio with Accedian Skylight
 Tools & Support
Tools & Support
Microbursts are invisible without extremely granular monitoring. Here’s how to find and monitor them so your customers stay happy.
Most service provider network links run at less than 10% average utilization. Since these links cost tens of thousands of dollars each to operate, it makes economic sense to aggregate them, feeding multiple low-utilization links into a smaller number of concentration points. For example, aggregation is often used in the access network, providing connectivity to many endpoints.
But, of course, anytime in life you create a concentration point, you also create the potential for bottlenecks.
You can see this in rather dramatic fashion when carrier aggregation is applied in an LTE-Advanced network to increase bandwidth, and therefore bitrate. Here, the technique is used to combine multiple LTE component carriers across available spectrum to support wider bandwidth signals, increase data rates, and improve network performance.
But, to support this type of aggregation, CSPs must use static or dynamic buffers to manage instantaneous oversubscription at different levels or ‘hops’ of the network. Too much buffering increases end-to-end latency, so buffers need to be adjusted depending on network applications.
And this is where the effect of buffering leads to the problem of burstiness and the very serious issues that can create.
Oh aggregation, what microburst havoc you create!
All this aggregation and buffering at each hop changes traffic patterns, creating packet jitter along the links and consequently increases traffic burstiness. This burstiness is made worse by instances when a multitasking OS (from an NFV component, for example) that’s running multiple applications gives CPU time to the network process; it sends as much data as it can in the shortest time.
All of these factors contribute to make network traffic very bursty. This wouldn’t be an issue if you could easily detect all the bursts, identify their causes, and adjust network operations parameters to prevent user experience issues.
But, not all bursts are easily detected. In fact, some are invisible without extremely granular sampling frequency.
The invisible but deadly microburst
Microbursts—rapid bursts of data packets sent in quick succession, leading to periods of full line-rate transmission that can overflow packet buffers at different layers of the network—are both common and difficult to manage or prevent because they’re hard to detect and monitor.
Even though microbursts are short-lived (milliseconds), they can and do cause significant network and application performance degradation in the form of increased latency, jitter, and packet loss. The impact is particularly severe with applications that require reliable, high-speed, low-latency data transmissions, like high frequency trading in financial networks or 5G ultra-reliable low latency communications services (uRLLC).
Most CSPs use monitoring tools that provide data at a resolution of minutes, or in best case seconds. This is granular enough to measure average bandwidth, but falls far short of the mark to detect microbursts. Since microbursts last a fraction of a second, they can easily hide in a 1-second or even 100-millisecond average.
The graph below shows a high-level representation of sampling frequency on the same data set with microbursts present. By increasing the sampling frequency (from 100ms to 1ms) the impact of microbursts on committed information rate (CIR) becomes obvious.
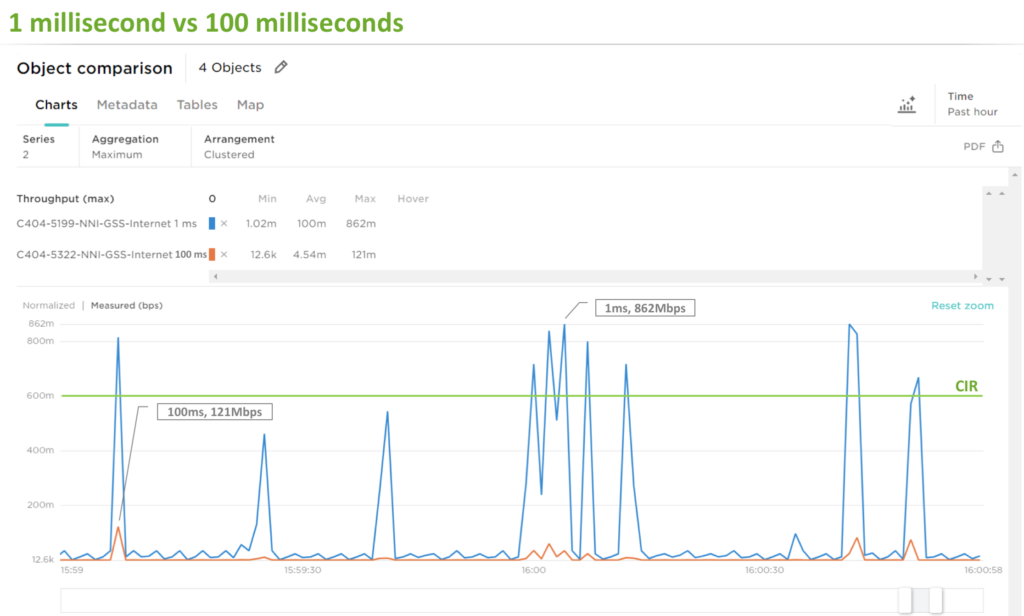
To identify potential capacity issues, it’s obvious you need a tool that’s able to monitor a network in real time at 1ms resolution. It exists!
Revealing invisible microbursts
Here’s some big news: the bandwidth utilization metering function (flowmeter) in Accedian’s Skylight solution now provides sampling granularity down to 1 millisecond. Microbursts can’t hide anymore!
The Skylight flowmeter passive metering function and reporting engine measures throughput (min, max, average) and packet statistics. It can be enabled at any location where a Skylight sensor is installed, for reporting at granularity as precise as 1 millisecond.
But wait, there’s more! Here are two other microburst detection-related components to note in Accedian’s Skylight solution suite:
- Skylight sensor: modules feature exceptionally accurate timestamping capabilities, supporting microsecond precision. This eliminates the variation caused by standard kernel drivers.
- Using Skylight performance analytics, Accedian’s cloud-native analytics platform for quality of experience (QoE) management, you can detect patterns in performance data to assist in correlating and isolating issues.
To wrap up, we thought it would be valuable to leave you with some tips on not just detecting but also preventing the negative effect of microbursts.
Microburst havoc, begone!
Methods to minimize the impact of microbursts are particular to each CSP’s specific network characteristics. But, to generalize, here are a few potential remedies.
Adaptive Buffering
Improvements to switching architectures now makes it possible to forward packets with minimal delay. Cut-through switches do not store the packets in most cases and can forward them in microsecond. However, if congestion builds (due to microbursts), packets need to be queued within a switch. Some switches have a few kilobytes of ingress packet memory per port. These architectures can handle small amounts of congestion when all ports are congested at the same time.
Adaptive buffer allocation consists of dynamically allocating buffering to the ports that need it when congestion is created by microbursts. Packets get forwarded in cut-through mode with limited buffering in normal cases. When congestion occurs, each port can use dynamic buffering to store packets, until the congestion clears up. The dynamic allocation of packet buffers results in limiting the impact of sudden increase in bandwidth and thus avoids packet loss. (However, this does impact overall packet latency.)
Shaping
Once microburst are detected and pinpointed to specific areas of the network, shaping techniques can be applied to smooth out traffic patterns and consequently reduce burst. These shaping techniques can be targeted to specific, latency-sensitive areas of the network.
Traffic shaping is a bandwidth management technique used which delays some or all packets to bring them into compliance with a desired traffic profile. However, standard traffic shaping is unable to effectively smooth out microbursts, and the granularity of most shapers is not sufficient to process traffic at this speed. An alternative called micro-shaping—optimizing bandwidth on a per-packet basis—is able to cost-effectively groom microbursts in a lossless manner providing much better bandwidth capacity utilization (fill) without the packet discard associated with more ‘lumpy’, coarse shaping techniques.
Splitting bursty applications or dedicating bandwidth
In certain situations, it’s possible to re-engineer parts of the network that are less latency sensitive, to handle bursty (and possibly less important) applications. In such cases, traffic is sent on specific paths and /or classes of service (CoS).
There are also more simplified options such as increasing bandwidth to allow burstier traffic or policing lower-priority applications in some parts of the network.